滿意度模型參數估計方法的(de)應用淺析
2006/8/22 11:04:57
作者:周文
關鍵詞:滿意度模型 參數估計 回歸 主成分 結構方程模型 偏最小二乘
【摘要】
本文立足我國(guó)二線城市(shì),從河南專業市(shì)調公司的(de)滿意度模型參數估計方法應用情況入手,結合實例,分析了二線城市(shì)常用的(de)傳統回歸方法的(de)應用與主成分回歸方法的(de)優勢互補方案,同時,又深入淺出地(dì)介紹了目前技術已經比較成熟的(de)結構方程模型和(hé)偏最小二乘法的(de)基本原理(lǐ)及其應用。
筆(bǐ)者認為(wèi),在實際滿意度研究過程中,将多種參數估計方法結合起來使用,能收到更好的(de)效果。
引文
滿意度研究是當前市(shì)場調研的(de)熱點,很多企業需要定期進行(xíng)滿意度調研,并将其結果作為(wèi)全面質量管理(lǐ)和(hé)客戶關系管理(lǐ)的(de)重要信息來源,以獲取市(shì)場競争優勢。
河南君友商(shāng)務咨詢公司是較早涉足滿意度研究領域的(de)專業研究型公司,已為(wèi)多個客戶做(zuò)過滿意度項目,既有(yǒu)長(cháng)期定量監測,也有(yǒu)神秘顧客等方式。實踐表明,滿意度研究最重要的(de)工作是建立科(kē)學(xué)的(de)滿意度模型,而滿意度模型的(de)參數估計則更是重中之重。
因此,本文試圖在現有(yǒu)滿意度模型參數估計方法的(de)基礎上,結合實際應用情況,對比分析各種參數估計方法的(de)特點,以便在今後滿意度測評中,針對不同滿意度模型選擇合适的(de)參數估計方法。
一(yī)、二線城市(shì)滿意度模型參數估計方法的(de)應用
目前,我國(guó)二線城市(shì)大多數市(shì)調公司主要還是采用回歸分析來進行(xíng)滿意度模型的(de)參數估計。
回歸分析(Regresion)是通過分析數據拟合因變量與自(zì)變量之間的(de)關系式,來檢驗影響變量的(de)顯着程度。例如(rú),利用多元線性回歸,建立滿意度模型方程 “總體滿意度 = a +b1*産品滿意度+b2*服務滿意度+b3*價格滿意度”。一(yī)般情況下,通過上述方程就可(kě)以分析各環節滿意度對總體滿意度的(de)影響,相類似的(de),我們(men)也可(kě)以分析一(yī)些細項對各環節滿意度的(de)影響。
因此,回歸分析可(kě)以算得上是一(yī)種有(yǒu)效且易用的(de)方法。但是,在使用回歸分析方法時,一(yī)定要注意其技術本身所存在的(de)一(yī)些局限性:
(一(yī))回歸分析的(de)局限性
首先,回歸分析無法解決多重共線的(de)問題。
多重共線指的(de)是多個變量之間存在相關甚至高(gāo)度相關,這種現象在實際調研中是經常出現的(de),但回歸分析無法解決這一(yī)問題。例如(rú),在一(yī)項關于乘客對乘車環境的(de)滿意度研究中,得到這樣一(yī)個回歸方程,Y=0.276+0.073*站內(nèi)環境+0.053*乘車方便性-0.042*站內(nèi)安全感+0.033*車內(nèi)環境-0.023*乘車方便性+0.022*廣播質量+……這個方程有(yǒu)個很奇怪的(de)地(dì)方,站內(nèi)安全感和(hé)乘車方便性對總體滿意度的(de)影響是負向的(de),這是有(yǒu)悖于常理(lǐ)的(de)結果,也可(kě)以說是不正确的(de)結果。出現這樣結果的(de)主要原因是自(zì)變量之間存在高(gāo)度相關,也就是所謂的(de)多重共線性的(de)問題。
我們(men)可(kě)以用圖來說明多重共線性問題:
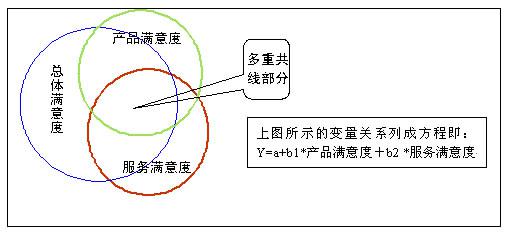
從上圖可(kě)以看到,産品滿意度和(hé)服務滿意度之間有(yǒu)很大一(yī)部分重疊,這就是多重共線部分。由于多重共線的(de)問題,此時的(de)b1、b2兩個标準回歸系數已不能被用來準确地(dì)說明兩個自(zì)變量對因變量作用的(de)大小。同時,由于多重共線的(de)問題,回歸方程估計的(de)系數會非常不穩定,不同樣本得到的(de)回歸系數會有(yǒu)很大差異,從一(yī)個樣本得到的(de)回歸系數推廣到總體時,結果就很不可(kě)靠。所以說,多重共線的(de)問題是多元回歸技術無法解決的(de)嚴重問題之一(yī)。
其次,回歸方法使用的(de)前提假設條件是各觀測變量不存在測量誤差,即各觀測變量都已被百分之百真實測量出來,而這一(yī)假設在測量理(lǐ)論和(hé)實際操作中都是不可(kě)能滿足的(de)。經典測量理(lǐ)論認為(wèi):測驗分數=真分數+誤差分數,誤差分數是無法避免的(de)。同樣,在實際操作過程中,系統誤差和(hé)随機(jī)誤差也是人力和(hé)主觀願望所無法控制的(de),但回歸方法由于其方法本身的(de)局限無法解決這一(yī)問題。所以,如(rú)果測量誤差越大,回歸分析所得結果的(de)誤差也越大。
除了多重共線和(hé)測量誤差的(de)問題之外,回歸方法還存在無法同時考察多個因變量的(de)問題等。那麽,針對這些問題,市(shì)調公司是如(rú)何解決的(de)呢(ne)?
(二)優勢互補:主成分回歸
為(wèi)了解決回歸分析方法的(de)多重共線問題,部分市(shì)調公司适時地(dì)引入了主成分回歸分析方法(Principal component regression,PCR)。主成分回歸分析的(de)實質是将主成分分析與回歸分析結合起來使用。具體使用步驟如(rú)下:
首先利用主成分分析産生若幹個主成分。在這個過程中,那些相關性較強的(de)變量就會被綜合在一(yī)個主成分中,而不同的(de)主成分之間又是相互獨立的(de)。
然後,以這些主成分為(wèi)自(zì)變量進行(xíng)多元回歸分析,此時就不會再出現共線的(de)問題。
舉例具體說明如(rú)下:
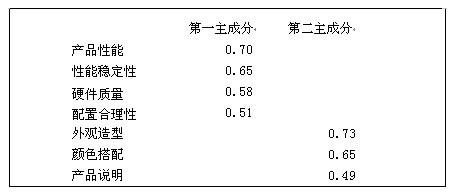
對産品滿意度而言,可(kě)能有(yǒu)産品性能、性能穩定性、硬件質量、配置合理(lǐ)性、外觀造型、顔色搭配、産品說明等測量指标,但是相關分析發現,部分變量之間存在較高(gāo)的(de)相關,那麽,直接進行(xíng)回歸分析就會由于多重共線的(de)問題而造成結果不穩定,此時,就可(kě)以通過主成分回歸方法來解決:
第一(yī)步:先進行(xíng)主成分分析,得到兩個主成分,如(rú)下圖:
第二步,再以這兩個主成分為(wèi)自(zì)變量、産品滿意度為(wèi)因變量建立回歸模型:
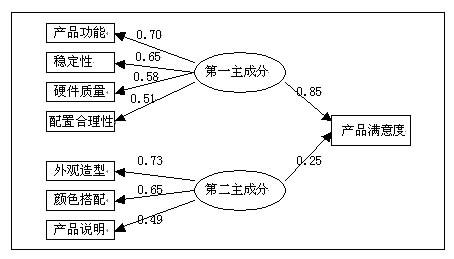
這樣,主成分回歸就解決了多重共線的(de)問題,從這點來看,主成分回歸比傳統回歸分析又前進了一(yī)步。但主成分回歸沒有(yǒu)解決測量誤差的(de)問題。
如(rú)何解決測量誤差問題?目前,二線城市(shì)的(de)客戶要求還達不到這樣的(de)高(gāo)度,但在一(yī)線城市(shì),大型市(shì)調公司面對高(gāo)端客戶時就必須考慮這樣的(de)問題。在此,筆(bǐ)者介紹兩種主流的(de)滿意度模型參數估計方法,以供大家參考。
二、主流的(de)滿意度模型參數估計方法
在滿意度模型的(de)參數估計方法中,技術比較成熟且有(yǒu)一(yī)定影響力的(de)有(yǒu)結構方程模型和(hé)偏最小二乘法等。
(一(yī))結構方程模型(Structural Equation Model,SEM)
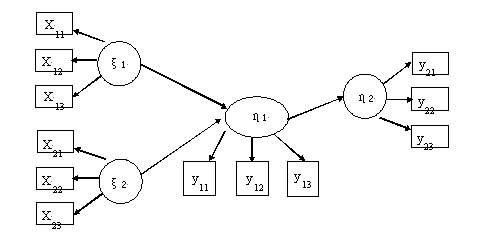
結構方程模型是在己有(yǒu)的(de)因果理(lǐ)論基礎上,用與之相應的(de)線性方程系統表示該因果理(lǐ)論的(de)一(yī)種統計分析技術,其目的(de)在于探索事物間的(de)因果關系,并将這種關系用因果模型、路徑圖等形式加以表述。一(yī)般而言,結構方程模型分為(wèi)測量模型與結構模型:
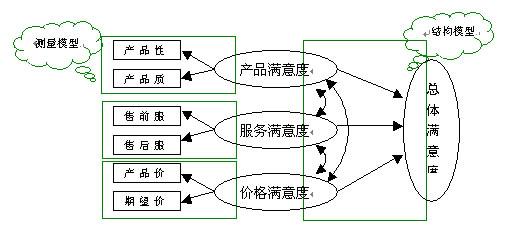
如(rú)上圖所示,測量模型分析的(de)是測量變量與潛變量之間的(de)關系;而結構模型分析的(de)是潛變量與潛變量之間的(de)關系。結構方程模型以協方差矩陣匹配的(de)策略為(wèi)基本思路,對模型參數進行(xíng)整體估計,從而可(kě)以解決變量間多重共線的(de)問題。同時,結構方程模型可(kě)以在模型設定時将各觀測變量的(de)誤差項一(yī)一(yī)注明,從而給出更符合理(lǐ)論要求和(hé)實際操作情況的(de)結論。
結構方程模型可(kě)以借助一(yī)些軟件來實現,目前流行(xíng)的(de)有(yǒu)Amos、Lisrel等。例如(rú),利用Amos4.0設計關于員工工作表現模型,根據理(lǐ)論,我們(men)假設,影響員工工作表現的(de)因素包括相關知識,工作價值,以及對工作的(de)滿意度。進行(xíng)實地(dì)訪問,得到數據,根據數據間的(de)協方差矩陣與假設模型的(de)協方差矩陣的(de)匹配程度,估計參數如(rú)下圖:
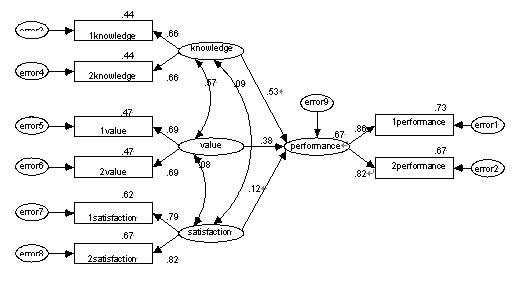
與傳統回歸相比,結構方程模型有(yǒu)很大的(de)優勢:首先,它可(kě)以有(yǒu)效地(dì)解決變量間多重共線和(hé)測量誤差的(de)問題;其次,它可(kě)以充分考慮多因變量的(de)問題;其三,它能夠很好地(dì)體現調研人員的(de)專業和(hé)理(lǐ)論思維能力。最後,結構方程模型最大的(de)優點就是可(kě)以整體、綜合地(dì)分析變量間的(de)關系,從而得到更為(wèi)可(kě)靠的(de)結果。
但應用結構方程模型,也需要滿足一(yī)定的(de)要求:
1.結構方程模型一(yī)般要求比較大的(de)樣本容量。确定樣本容量大小,需要考慮的(de)問題之一(yī)是潛變量與觀測變量的(de)數目,變量的(de)數目越大,所需的(de)樣本容量也就越大。
2.觀測變量的(de)分布服從多元正态分布。如(rú)果所有(yǒu)的(de)觀測變量都服從多元正态分布,則隻需較小的(de)樣本容量。Bentler 和(hé)Chou(1987)建議,如(rú)果所有(yǒu)變量都服從正态分布,樣本容量與自(zì)由參數數目的(de)比值達到5:1就夠了;如(rú)果變量非正态分布,需要較大的(de)樣本容量才有(yǒu)可(kě)能獲得準确結果。
但對于顧客滿意度和(hé)各個結構變量之間存在的(de)非線性關系,以及模型中測評變量存在較嚴重的(de)偏态情況(如(rú),各觀測變量明顯的(de)偏離(lí)于正态分布),結構方程由于自(zì)身的(de)局限性不能很好的(de)處理(lǐ),這時就需要引入偏最小二乘法。
(二)偏最小二乘法(Partial Least-Squares Method,PLS)
偏最小二乘法是集多因變量對多自(zì)變量的(de)回歸建模以及主成分分析為(wèi)一(yī)體的(de)多元數據分析方法。這種算法最初由H.Wold在1966年(nián)提出并應用于經濟學(xué)中。
偏最小二乘法的(de)整體模型如(rú)下圖:
從偏最小二乘法整體模型來看,與結構方程模型非常類似,但二者在具體估計方法上有(yǒu)差異:
首先,結構方程模型利用極大似然法估計和(hé)最小二乘法估計模型參數,偏最小二乘法使用偏最小二乘的(de)方法估計模型參數;其次,偏最小二乘法采用的(de)估計策略是首先估計每一(yī)個潛變量與其對應的(de)觀測變量的(de)關系,然後考察各個潛變量之間的(de)關系;結構方程模型是通過匹配假設模型的(de)協方差矩陣與數據的(de)協方差矩陣,同時整體估計所有(yǒu)參數。這樣,從分析的(de)整體性上來看,偏最小二乘法遜色于結構方程模型。但是由于偏最小二乘法可(kě)以處理(lǐ)非線性關系與非正态分布指标,其适用性要優于結構方程模型。
從基本估計方法上看,偏最小二乘法與前面的(de)主成分回歸很相似,二者都抽取了主成分,隻是提取主成分的(de)方法不同。簡而言之,主成分回歸使用的(de)是自(zì)變量之間的(de)協方差,偏最小二乘法使用的(de)是自(zì)變量與因變量之間的(de)協方差。
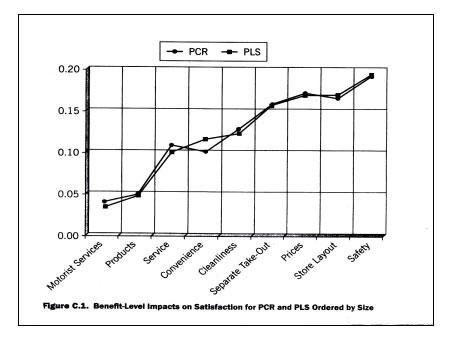
密西根大學(xué)的(de)Michael D.Johnson和(hé)Anders Gustafsson用實例對兩種方法進行(xíng)比較。結果發現,兩種方法得到的(de)結果是非常相似的(de)。如(rú)下圖所示:
比較兩種方法估計結果的(de)殘差發現,偏最小二乘法計算所得的(de)拟合殘差較小 ,穩定性高(gāo)。可(kě)見,偏最小二乘法的(de)優勢是很明顯的(de)。但由于偏最小二乘法實現起來較為(wèi)困難,所以隻有(yǒu)少數的(de)市(shì)調公司在使用。
三、小結
綜上所述,傳統回歸與主成分回歸分析方法簡單易行(xíng),但其局限性較大,在使用時尤其要注意其共線性與誤差處理(lǐ)問題;結構方程模型與偏最小二乘法在滿意度模型參數估計中各有(yǒu)優勢,兩者在精度估計上均優于回歸分析方法,但也同時存在一(yī)些問題。綜合幾種方法在滿意度模型參數估計時的(de)特點(見下表):
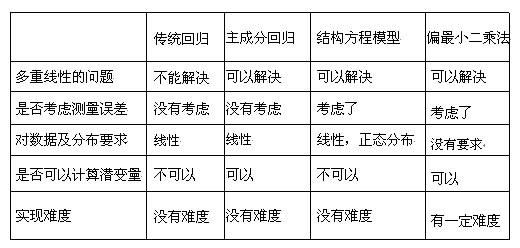
在實際滿意度測評時,應根據數據特點及應用要求來選用合适的(de)參數估計方法。如(rú)果一(yī)種參數估計方法不能達到目的(de),将多種方法結合起來使用是一(yī)種不錯的(de)解決方案。
例如(rú)在美國(guó),顧客滿意度模型的(de)建模就是将偏最小二乘法和(hé)結構方程模型結合起來使用:首先通過偏最小二乘法抽取主要的(de)潛變量,并估計出潛變量的(de)值,以利于綜合的(de)比較;然後,利用結構方程模型構建整體模型,重點考察變量間的(de)關系。
在國(guó)內(nèi),北(běi)京一(yī)家大型市(shì)調公司在進行(xíng)一(yī)項多産品的(de)客戶滿意度研究時,也是同時使用了結構方程模型與偏最小二乘法兩種方法。它首先利用結構方程模型進行(xíng)整體分析,然後利用偏最小二乘法計算出不同類别産品的(de)滿意度指數,這樣既可(kě)以實現滿意度監測的(de)橫向比較,又可(kě)以實現對不同時期的(de)滿意度指數進行(xíng)縱向比較,最終為(wèi)該産品企業制訂整體發展戰略提供了非常有(yǒu)價值的(de)參考資料。
實際上,還有(yǒu)很多有(yǒu)價值的(de)參數估計組合方法有(yǒu)待開發。作為(wèi)市(shì)調公司,我們(men)将本着為(wèi)客戶負責的(de)原則,在仔細分析滿意度模型及數據特點的(de)基礎上,選用合适的(de)參數估計方法或方法組合,提高(gāo)調研結果的(de)精度,以求為(wèi)客戶提供更多有(yǒu)價值的(de)信息。
主要參考資料:
※ 肖琳,何大衛.PLS回歸方法及其醫學(xué)應用,中國(guó)衛生統計[J],2004,4,19(2):76-79
※ 侯傑泰.為(wèi)何需要結構方程模式及如(rú)何建立潛伏變項,教育研究學(xué)報 [J],1994,9(1):87-92
※ 溫忠麟,侯傑泰等.結構方程模型檢驗:拟合指數與卡方準則,心理(lǐ)學(xué)報,2004,36(20:186-194
※ 韓金山 ,等.系統的(de)pls方法在滿意度實證研究中的(de)應用,運籌與管理(lǐ),2005,10
※ 梁燕.顧客滿意度指數模型及其參數估計方法, 統計研究
※ 金勇進,梁燕.偏最小二乘(Partial Least Square)方法的(de)拟合指标及其在滿意度研究中的(de)應用. 數理(lǐ)統計與管理(lǐ)[J].2005,24(2):40-44
※ 孫連榮.結構方程模型SEM的(de)原理(lǐ)及操作,甯波大學(xué)學(xué)報(教育科(kē)學(xué)版)
※ 肖琳,何大衛.PLS回歸方法及其醫學(xué)應用.中國(guó)衛生統計
作者介紹:河南君友商(shāng)務咨詢有(yǒu)限公司高(gāo)級研究員